QPHIL: Quantizing Planner for Hierarchical Implicit Q-Learning
Abstract
Offline Reinforcement Learning (RL) has emerged as a powerful alternative to im itation learning for behavior modeling in various domains, particularly in complex long range navigation tasks. An existing challenge with Offline RL is the signal- to-noise ratio, i.e. how to mitigate incorrect policy updates due to errors in value estimates. Towards this, multiple works have demonstrated the advantage of hier archical offline RL methods, which decouples high-level path planning from low- level path following. In this work, we present a novel hierarchical transformer- based approach leveraging a learned quantizer of the state space to tackle long horizon navigation tasks. This quantization enables the training of a simpler zone-conditioned low-level policy and simplifies planning, which is reduced to discrete autoregressive prediction. Among other benefits, zone-level reasoning in planning enables explicit trajectory stitching rather than implicit stitching based on noisy value function estimates. By combining this transformer-based planner with recent advancements in offline RL, our proposed approach achieves state-of- the-art results in complex long-distance navigation environments.
1. Scaling Offline GCRL to Long‑Range
Challenge: Learn a policy $\pi(a\mid s,g)$ from imperfect demonstrations $\mathcal{D}=\{\tau\}$ that reaches goal $g$ from state $s$ offline.
Limits: Value‑based RL suffers from noisy estimates, especially for long horizons.
Question: How can we reduce value‑function noise while keeping strong path‑following performance?
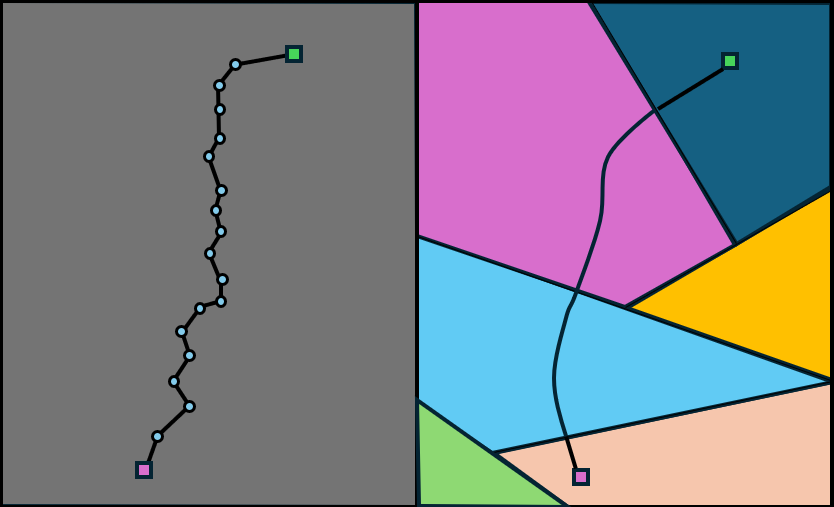
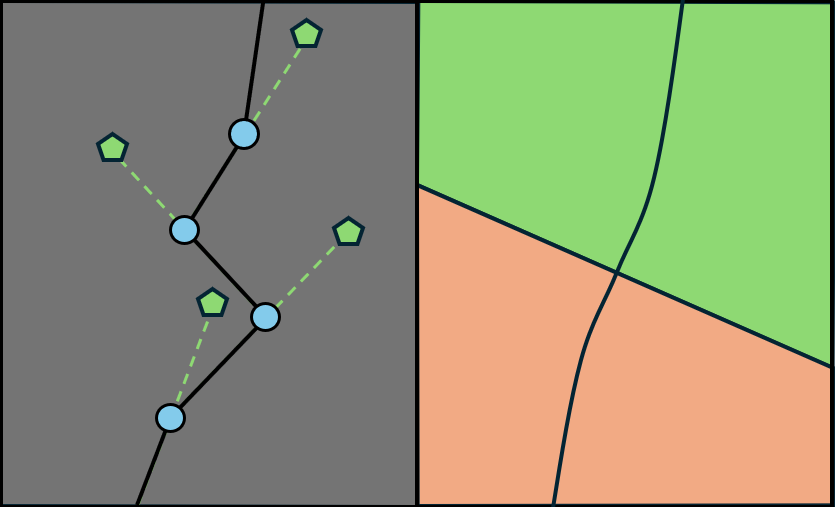
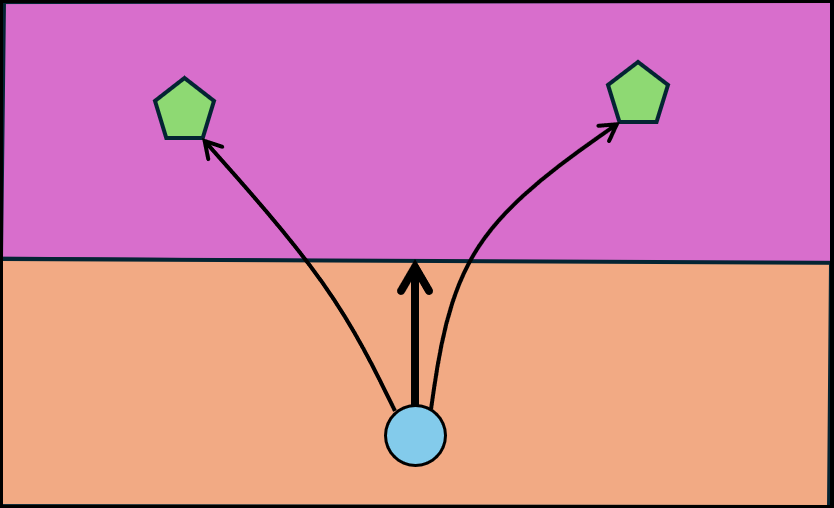
QPHIL learns discrete landmarks and leverages them to:
- • Simplify sub‑goal planning with discrete tokens.
- • Avoid noisy high‑frequency sub‑goal updates.
- • Relax conditioning from sub‑goals to landmarks.
2. QPHIL: Architecture & Inference
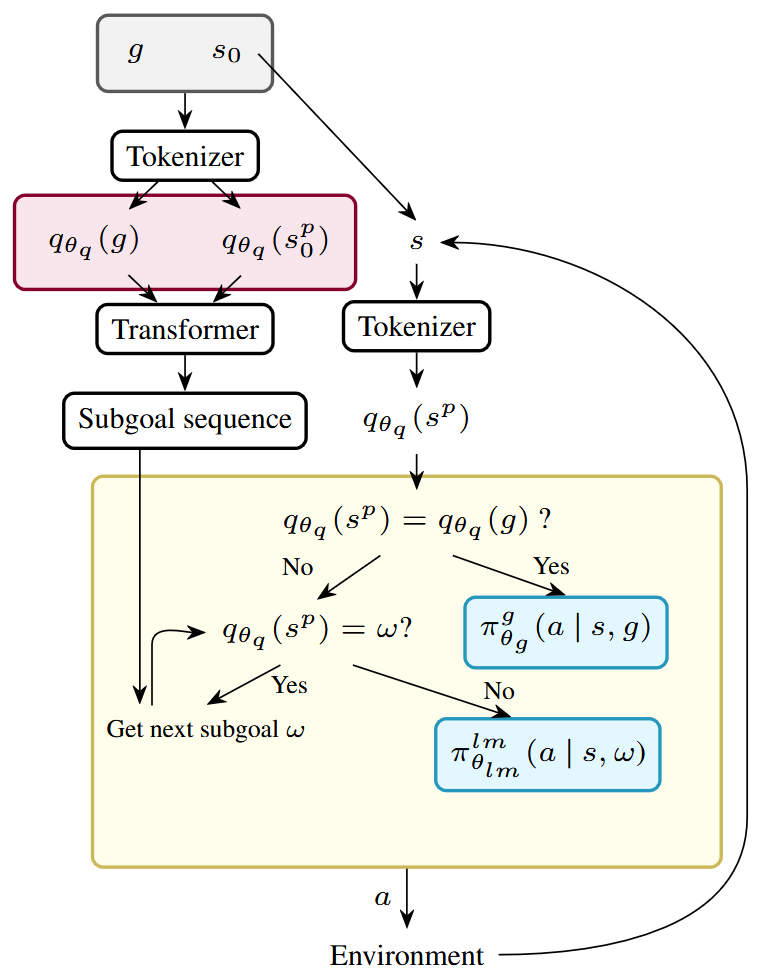
Open‑loop inference pipeline
QPHIL operates through four components:
3. QPHIL: Training & Losses
QPHIL components are trained sequentially:
Quantizer $q_{\theta_q}: \mathcal{S}^p \to \Omega$ with encoder $f^e_{\theta_e}$ and codebook $z$, learned by minimizing $\mathcal{L}_{\text{quantizer}}$, combination of Contrastive loss $\mathcal{L}_{\text{contrastive}}$ and VQ‑VAE loss $\mathcal{L}_{\text{VQ‑VAE}}$.
Planner $\pi^{p}_{\theta_p}: \Omega_H \times \Omega \to \Omega_P$, learned by minimizing the log‑likelihood loss $\mathcal{L}_{\text{planner}}$ over compact landmark sequences.
Landmark policy $\pi^{\text{lm}}_{\theta_{lm}}$ and Goal policy $\pi^{g}_{\theta_{g}}$ are learned with Implicit Q‑Learning (IQL).
4. Environments & Datasets
Environments: AntMaze (Medium, Large, Ultra, Extreme)


Datasets: trajectories $\mathcal{D}$ of two types:
- Diverse: random start / goal positions.
- Play: curated start / goal positions.
5. Key Results
QPHIL on AntMaze: scales with navigation range, matching SOTA on small mazes and greatly surpassing prior work on harder ones.
| Environment | GCBC | GCIQL | GCIVL | HGCBC w/o repr | HGCBC w/ repr | HIQL w/o repr | HIQL w/ repr | QPHIL |
|---|---|---|---|---|---|---|---|---|
| medium‑diverse | 65±11 | 80±8 | 82±8 | 46±11 | 13±9 | 92±4 | 92±4 | 92±4 |
| medium‑play | 60±11 | 80±9 | 84±9 | 48±9 | 10±8 | 90±5 | 92±4 | 91±2 |
| large‑diverse | 10±5 | 21±10 | 59±13 | 78±7 | 18±8 | 88±4 | 85±8 | 82±6 |
| large‑play | 9±5 | 25±12 | 50±9 | 79±7 | 14±13 | 87±7 | 84±7 | 80±3 |
| ultra‑diverse | 16±9 | 20±8 | 6±5 | 71±12 | 32±24 | 71±7 | 71±12 | 62±7 |
| ultra‑play | 15±10 | 20±10 | 10±6 | 64±12 | 13±15 | 63±20 | 74±23 | 62±4 |
| extreme‑diverse | 9±6 | 12±7 | 5±10 | 6±14 | 0±4 | 14±17 | 20±20 | 40±13 |
| extreme‑play | 8±7 | 16±7 | 0±0 | 11±10 | 4±8 | 12±16 | 28±27 | 50±7 |
6. Ablations
- Contrastive loss is crucial for good quantization and performance.
- VQ‑VAE reconstruction loss eases hyper‑parameter tuning.
- Success rate plateaus beyond a reasonable codebook size.
- Out‑of‑distribution positions share landmarks with neighbours.
- Under diverse initial states/goals, QPHIL still performs.
7. Conclusion
QPHIL leverages learned landmark representations to achieve state‑of‑the‑art long‑range planning on offline GCRL navigation benchmarks.
Limits: Currently focused on navigation; may not transfer to more intricate planning domains.
Future work: Scale landmark dimension, tackle higher‑dimensional problems, and exploit QPHIL’s interpretability.